1. pandasで地味に難しい条件に応じた置換や代入
pandasを利用していて地味に難しいのが条件に応じた置換や代入です。
リスト内包表記が便利で柔軟でコードを読みやすいので好みなのですが処理が遅そうです。
そこでmaskを使用した場合の処理時間と比較してみました。
やはりリスト内包表記の処理が遅いことが分かりました。
データ件数が多い場合にはmaskを使用した方法を推奨します。
1.1. 変換例
例えば下記のような置換。
-
aの値が5未満の場合はaの値をそのままbに代入
-
aの値が5以上8未満の場合はa×10の値をbに代入
-
aの値が8以上の場合はa×100の値をbに代入
具体的にはこのような結果です。
| a | b |
|---|---|
0 |
0 |
1 |
1 |
2 |
2 |
3 |
3 |
4 |
4 |
5 |
50 |
6 |
60 |
7 |
70 |
8 |
800 |
9 |
900 |
1.2. データ作成
今回使用するデータを作成します。
変数a:(0〜9までの値を持つ10行)だけの簡単なデータです。
import pandas as pd
dat = pd.DataFrame(
dict(
a=range(10)
)
)| a |
|---|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
2. リスト内包表記による実装
リスト内包表記は強力な記法で便利なのでどこでも使いたくなってしまいます。
ただしループ処理なのでデータ件数が多くなると処理時間が気になってきます。
dat2 = (
dat
.assign(
b=[
v * 100 if v >= 8
else v * 10 if v >= 5
else v
for v in dat.a
]
)
)3. pandas.Series.maskによる実装
pandasにはmaskという今回のような処理のためのメソッドが用意されています。
ただし使い勝手はよくありません。
一つのmaskで一つの置換だけに対応できます。
今回のような複数条件に対応するためにはmaskを重ねます。
重ねる順番に注意です。
dat2 = (
dat
.assign(
b=dat.a
.mask(
dat.a >= 5,
dat.a*10
)
.mask(
dat.a >= 8,
dat.a*100
)
)
)4. 処理時間の計測
リスト内包表記とmaskによるそれぞれの方法で処理時間を計測しました。
データ件数も10, 100, 100, ・・・, 10000000件までのデータで試しました。
実際の計測した処理時間が下記です。
| n | times_by_mask | times_by_list |
|---|---|---|
10 |
0.0033996105194091797 |
0.0010013580322265625 |
100 |
0.003099203109741211 |
0.0007476806640625 |
1000 |
0.003092527389526367 |
0.001218557357788086 |
10000 |
0.003689289093017578 |
0.0064542293548583984 |
100000 |
0.008987188339233398 |
0.05704998970031738 |
1000000 |
0.04408526420593262 |
0.5445349216461182 |
10000000 |
0.5032713413238525 |
5.458960056304932 |
データ件数と処理時間の関係をグラフ化します。
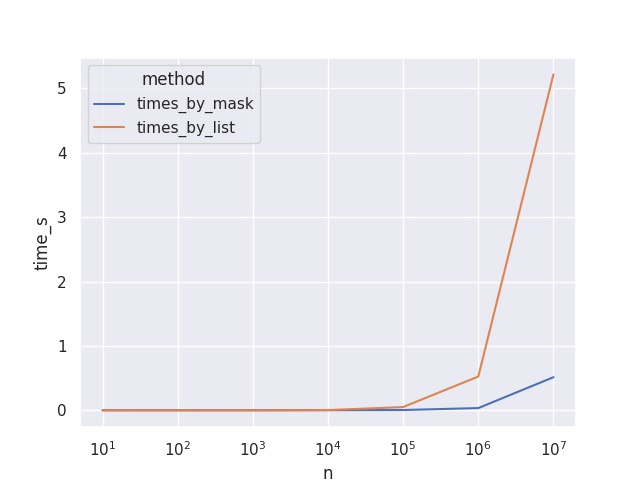
データ件数が少ない場合は処理時間の差が僅かですがデータ件数が多くなると無視できないほど大きな差になってしまいます。
5. まとめ
データが多い場合にはリスト内包表記の処理時間が無視できないほど大きくなってしまいました。
このような場合はmaskを使用して実装しましょう。